
Comment construire une stratégie “Customer Data Platform” (CDP) avec Microsoft ?
Customer Data Platform : construisez votre stratégie CDP avec Microsoft Customer Insights. Unification, segmentation, activation. Guide expert.
Lorsqu’une direction commerciale demande un dashboard intégrant les données e-commerce à l'équipe data, cette dernière en a bien souvent pour 6 mois minimum. En particulier lorsque les étapes sont opérées manuellement, de l’extraction au déploiement. Cependant, les résultats s’en font vite ressentir : lenteur chronique, équipes épuisées, business frustré. L'approche artisanale ne scale pas.
Le DataOps applique à la data les principes d'industrialisation du DevOps. Vous pouvez passer, dans certains cas, de 6 mois à quelques semaines pour livrer une source exploitable, avec une qualité garantie et une équipe sereine.
Dans cet article, nous décryptons cette approche : définition et positionnement, enjeux business, pratiques fondamentales, implémentation dans l'écosystème Microsoft et méthodologie de déploiement progressif.

Le DataOps désigne l'ensemble des pratiques qui appliquent les principes DevOps au domaine de la donnée. Plus concrètement, il transforme la production de données d**'un processus artisanal et lent en chaîne industrielle agile et fiable**.
Cette approche peut se résumer par la formule pédagogique suivante : DataOps = Data + DevOps + Méthode agile + Lean Manufacturing. Vous empruntez :
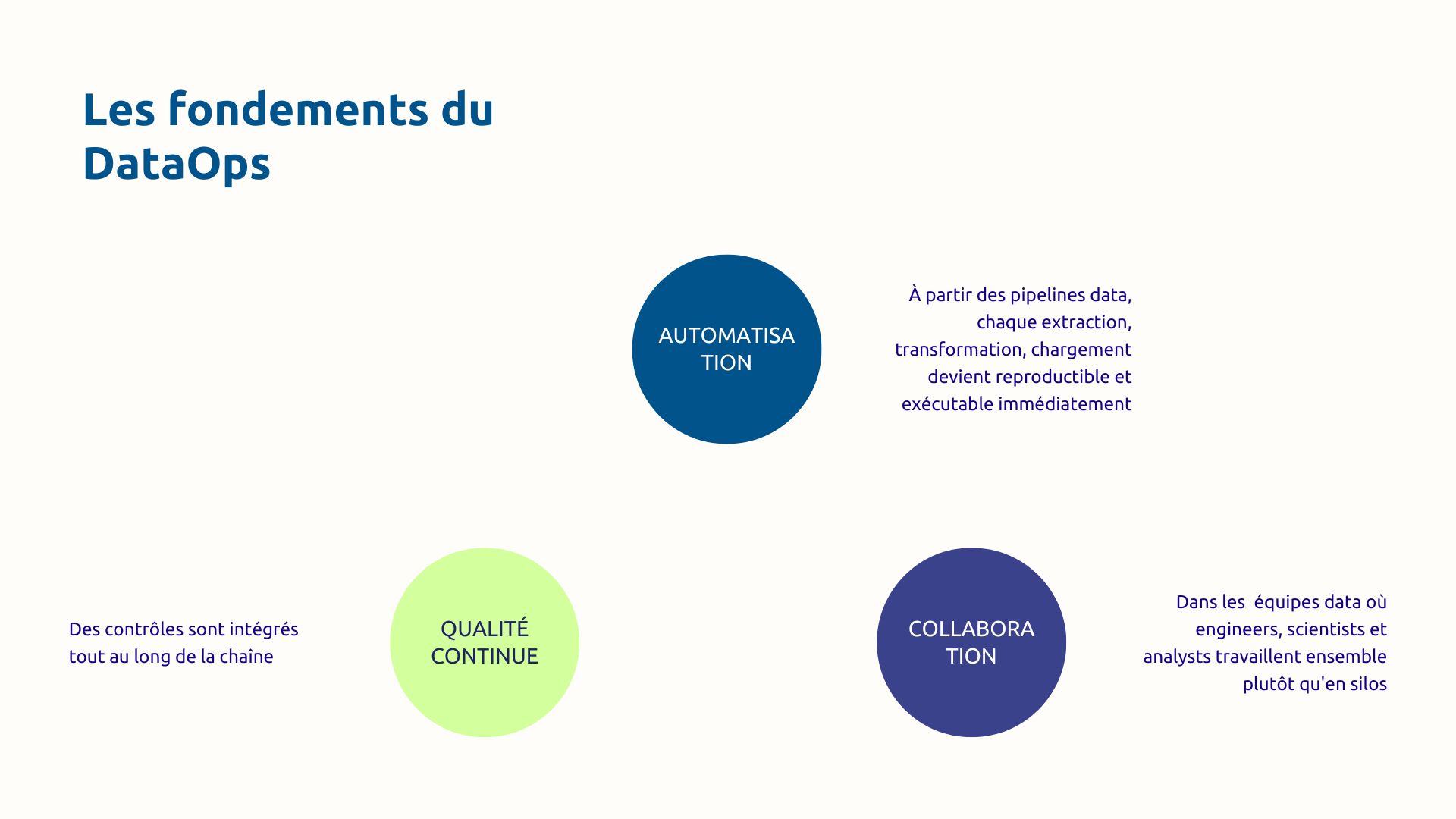
Ainsi, le DataOps correspond à une véritable culture, à un ensemble de pratiques supportées par des outils. Son périmètre couvre l'intégralité de la chaîne : de l'ingestion des sources à la consommation par les utilisateurs métiers, en passant par la transformation, la qualité, la gouvernance et le monitoring.
La confusion entre ces termes est fréquente. Le Data Engineering est une discipline technique qui consiste à construire des pipelines ETL et des architectures data. C'est le "quoi" : les compétences nécessaires pour manipuler et transformer des données à grande échelle.
De son côté, le DataOps est une méthode d'industrialisation du data engineering. C'est le "comment" : les pratiques pour exercer le data engineering de manière industrielle et reproductible. Un data engineer qui applique les principes DataOps version son code, le teste automatiquement et le déploie via CI/CD.
Quant au MLOps (Machine Learning Operations), c’est un sous-ensemble du DataOps focalisé spécifiquement sur les modèles de machine learning : déploiement, monitoring et maintenance des modèles ML en production. Le DataOps a un scope plus large qui englobe toute la chaîne data, que vous fassiez du ML ou non.
En premier lieu, la lenteur. En effet, chaque nouveau pipeline data devient un projet de plusieurs mois pendant que votre business attend.
Ceci s’aggrave avec les silos organisationnels où data engineers, scientists et analysts travaillent chacun dans leur coin, sans collaboration ni mutualisation des connaissances
De plus, la qualité des données reste aléatoire car vous testez manuellement en fin de chaîne et les erreurs sont découvertes en production par les utilisateurs finaux.
En outre, vous êtes condamné à recommencer de zéro à chaque projet : le code n'est ni documenté, ni mutualisé, ni versionné. Il n’est donc pas réutilisable.
Dernier symptôme, cette approche artisanale ne peut pas absorber la demande croissante. Ainsi ,votre équipe data devient submergée et se transforme en goulot d'étranglement. En effet, selon de nombreuses études de l'industrie, les data scientists passeraient jusqu'à 70% de leur temps à préparer les données et seulement 30% à faire de l'analyse et à piloter le machine learning. Ce sont de précieuses compétences qui sont ainsi gaspillées.

L'accélération du time-to-insight constitue le bénéfice le plus immédiat. Ceci s’explique par :
Par exemple, dans certains projets, là où l'intégration d'une nouvelle source e-commerce nécessitait 6 mois (développement du connecteur, transformation, contrôle qualité, mise en production), le DataOps peut ramener ce délai à deux semaines grâce à un connecteur réutilisable, des transformations automatisées, un déploiement via CI/CD et une qualité contrôlée en continu.
À propos, la garantie de qualité relève, via le DataOps, de la certitude systématique puisque d’abord, le testing automatisé vérifie chaque pipeline avant la production : volumétrie attendue, format correct, cohérence des données, respect des règles métiers.
De plus, le monitoring continu permet de déclencher des alertes automatiques si une anomalie est détectée. Enfin, l'observabilité apporte une traçabilité complète via le data lineage : vous savez d'où viennent les données et comment elles ont été transformées. Vous pouvez de nouveau être confiant et prendre des décisions business en toute sérénité.
Le troisième grand bénéfice du DataOps est la démocratisation de l'accès aux données via le self-service encadré, qui change la dynamique organisationnelle.
Ainsi, vos équipes marketing créent leurs propres rapports Power BI sur des données certifiées qualité, sans attendre deux mois qu'un data engineer leur construise un pipeline.
De même, la collaboration devient fluide grâce au code data partagé sur Git, à la documentation automatique et au data catalog accessible à tous. Sans oublier les feedback loops, qui permettent aux métiers de remonter rapidement leurs besoins et de déployer les correctifs.
L'automatisation n’est rien de moins que le socle technique du DataOps. L'Infrastructure as Code vous permet de traiter vos pipelines data comme du code versionnable et reproductible, défini en JSON, YAML ou Python. Plus besoin de reconfigurer manuellement chaque environnement.
Via des outils comme Azure Data Factory (ou Airflow pour des architectures hybrides) vous orchestrez l'enchaînement des tâches, la planification des exécutions et la reprise automatique sur erreur. Sachez que l'automatisation couvre toutes les étapes :
Votre pipeline Azure Data Factory est défini dans un template ARM sous forme de code. Il extrait des données de l'API Salesforce, les transforme avec Spark, puis les charge dans Synapse. Ce code est versionné sur Git et déployé automatiquement via Azure DevOps. Vous modifiez quelque chose ? Un simple commit Git déclenche l'exécution automatique des tests puis le déploiement.
Grâce aux tests unitaires, on vérifie chaque transformation séparément : la fonction SQL qui agrège les ventes doit produire le résultat attendu sur un jeu de données connu. Puis, avec les tests d'intégration, on valide le pipeline complet end-to-end sur des données de test.
Enfin, c’est par les tests de cohérence et de qualité que l’automatisation de la vérification des règles métiers est rendue possible :
Des frameworks comme Great Expectations, l’un des outils de référence pour la validation de données, permettent de définir ces attentes sous formes de critères puis de les valider automatiquement.
Attention, pour que ce soit bien un monitoring continu, il faut que ces tests soient réalisés à chaque commit sur Git, avant chaque déploiement vers la production et même en cours de production.
Par exemple, pour un pipeline qui transforme les données de ventes : Les tests unitaires vérifient que les agrégations SQL produisent les bons totaux. Les tests de cohérence et de qualité valident que la somme des ventes de tous les magasins égale la somme nationale. Les data quality checks vérifient qu'aucun chiffre d'affaires n'est négatif et qu'aucune date n'est dans le futur.
Git stocke l'intégralité de votre code data : pipelines ETL, transformations, tests, documentation. Chaque modification est tracée : qui l'a faite, quand, et pourquoi.
En outre, le workflow branches/pull requests structure la collaboration. De fait, vous développez une nouvelle feature sur une branche dédiée, vous testez, puis vous ouvrez une pull request pour revue par un senior data engineer qui valide l'approche avant de merger. Cette peer review garantit la qualité et diffuse les connaissances.
Avec une traçabilité complète, vous êtes toujours en mesure de savoir qui a modifié telle ou telle transformation. Dès lors, le rollback devient trivial car au moindre problème détecté vous n‘avez qu’à restaurer la version précédente en un clic.
Dans l'écosystème Microsoft, c’est Azure Repos qui facilite cette gestion de version pour vos assets data.
Vous ne pouvez pas gérer ce que vous ne mesurez pas. L'observabilité transforme une plateforme data opaque en système transparent et maîtrisable.
Le monitoring englobe trois dimensions :
L'alerting automatique est une fonctionnalité qui va prévenir votre équipe et ce, avant que les problèmes ne deviennent critiques.
Le data lineage complète le dispositif car il s’agit du traçage de l'origine des données et de toutes les transformations appliquées. Lorsqu'un problème survient, en utilisant cette fonctionnalité, vous remontez instantanément la chaîne pour identifier la source plutôt que de chercher à l'aveugle.
Dans l'écosystème Microsoft, tout cet arsenal d'observabilité s'appuie sur Azure Monitor et Application Insights pour les métriques techniques, Microsoft Purview pour le data lineage, et Power BI pour les dashboards de pilotage. Ces capacités sont désormais largement intégrées dans Microsoft Fabric.
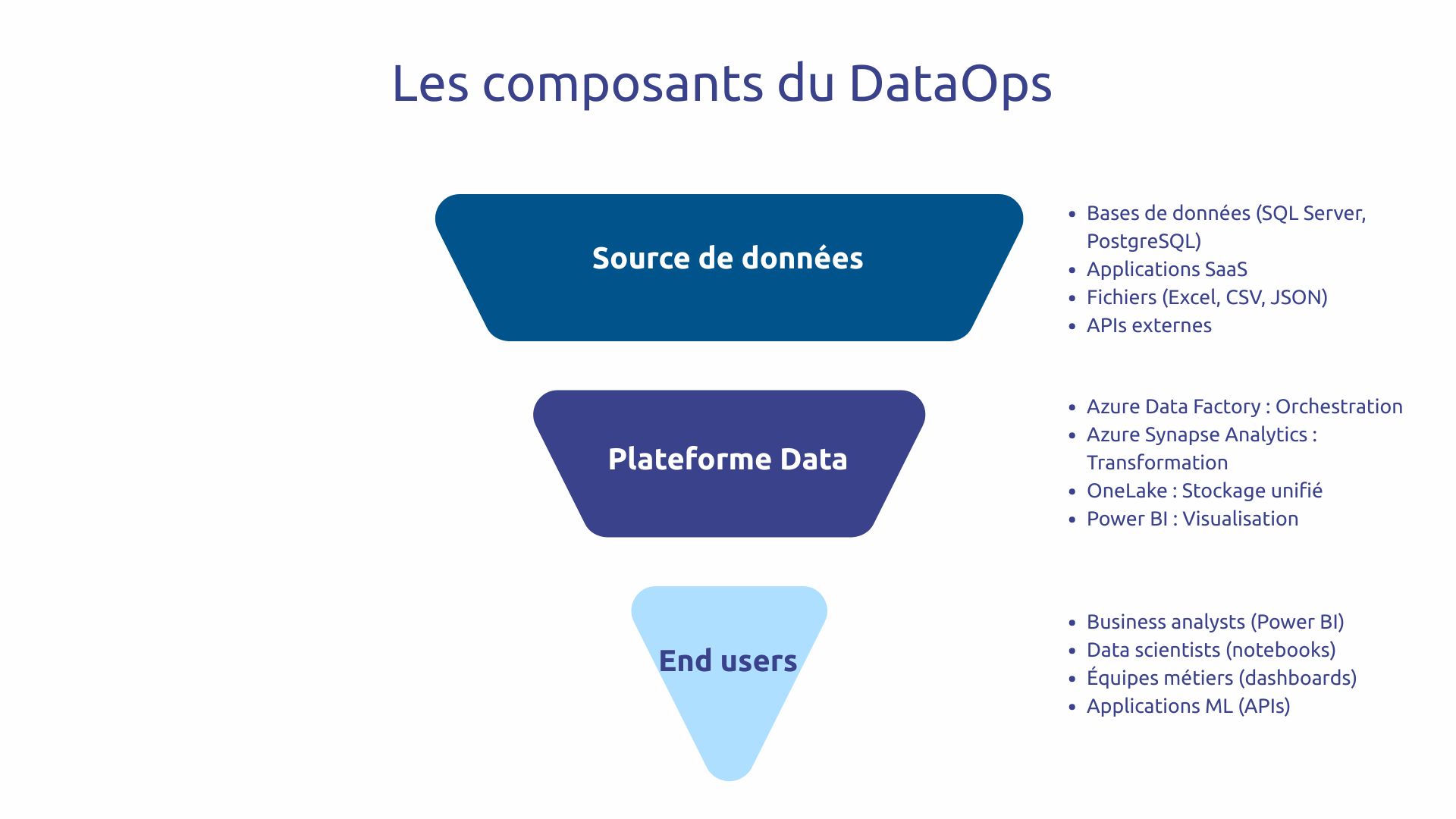
Azure Data Factory (ADF) orchestre vos pipelines data avec plus de 90 connecteurs natifs vers des sources diverses : bases de données, APIs, fichiers, applications SaaS. Cette richesse évite le développement de connecteurs custom pour chaque source.
En parallèle, Azure Synapse Analytics combine un entrepôt de données et des capacités avancées : requêtes analytiques performantes et puissance de transformation Spark pour de gros volumes. Ensemble, ADF et Synapse forment le duo extraction-transformation au cœur de votre chaîne data.
Toutefois, ce qui transforme ces outils en véritables plateformes DataOps, c'est leur intégration CI/CD native :
Azure DevOps apporte justement cette dimension automatisation et déploiement :
Fabric unifie dans une plateforme SaaS complète : data engineering, data warehouse, data science, real-time analytics et Power BI. Plus besoin de jongler entre plusieurs services séparés.
Cet effort repose sur OneLake, une couche de stockage logique unifiée pour toutes vos données dans un seul lac de données. Cette centralisation élimine les silos data qui compliquent traditionnellement la gouvernance et ralentissent l'accès.
Mais l'atout DataOps décisif de Fabric, c'est son intégration Git native. Vous versionnez l'intégralité du contenu Fabric : pipelines, notebooks, modèles sémantiques, rapports. Cette approche "Git-first" ancre le DataOps au cœur même de la plateforme plutôt que de le laisser en couche optionnelle.
Ainsi l'expérience développeur devient moderne et cohérente. Que vous fassiez du data engineering, de la data science ou du reporting, vous travaillez dans un environnement unifié avec les mêmes pratiques de versioning, testing et déploiement.
Toute transformation DataOps commence par comprendre précisément où vous en êtes aujourd'hui.
Alors commencez par cartographier votre patrimoine data : toutes vos sources de données, vos flux actuels et vos pipelines existants. Cette vision d'ensemble révèle souvent des surprises : sources oubliées, flux redondants, pipelines orphelins. Identifiez ensuite vos points de friction en vous posant les bonnes questions : où perdez-vous le plus de temps ? Quels pipelines cassent régulièrement ? Évaluez votre maturité actuelle sur un spectre allant du totalement manuel au totalement automatisé.
Sélectionnez ensuite un pipeline critique pour obtenir un quick win. Il s’agit d’un pipeline suffisamment important pour le business mais pas trop complexe techniquement et sur lequel l'amélioration sera visible immédiatement. Cette première victoire sert à démontrer la valeur du DataOps et à donner de l'élan pour la suite.
Puis, vous construisez les fondations de votre plateforme DataOps. Provisionnez l'infrastructure Azure : Data Factory, Synapse et Azure DevOps. Configurez ensuite vos environnements CI/CD multi-stages : développement pour expérimenter, test pour valider, production pour délivrer. Les pipelines Azure DevOps automatisent la promotion entre ces environnements.
Établissez des standards communs à l'équipe : comment structurer le code data, quelles conventions de nommage, quels tests sont obligatoires. Formalisez des data contracts qui clarifient les attentes entre producteurs et consommateurs de données. La formation des équipes aux pratiques DataOps est critique : vos data engineers doivent comprendre Git, le CI/CD, le testing automatisé.
Définissez enfin vos métriques de succès pour mesurer vos progrès : time-to-market pour nouveaux pipelines, taux de succès des déploiements, temps de résolution des incidents.
Élargissez progressivement le périmètre au-delà des pipelines pilotes. Vous industrialisez de nouveaux domaines data, vous intégrez de nouvelles sources, vous automatisez de nouveaux processus. Cette expansion se fait par vagues successives, en consolidant les acquis à chaque étape plutôt que de tout transformer d'un coup.
Ensuite, optimisez vos pipelines et réduisez vos coûts cloud. Les données de monitoring révèlent en effet les pipelines inefficaces qui consomment trop de ressources. Vous optimisez, vous dimensionnez correctement, vous éliminez le gaspillage.
En parallèle, cultivez l'amélioration continue via des reviews régulières. L'équipe analyse ce qui a bien fonctionné, ce qui a moins bien marché, et ce qu'il faut ajuster. Ces sessions créent un apprentissage collectif permanent. Au fil du temps, vous évoluez vers des capacités avancées : streaming temps réel, automatisation ML avec MLOps, optimisation avancée des performances.
Enfin, mesurez le ROI pour démontrer la valeur créée. Comparez vos métriques actuelles aux métriques initiales : time-to-market divisé par combien ? Taux d'incidents réduit de quel pourcentage ?
Là où vous subissiez des projets interminables, des incidents récurrents et des équipes épuisées, avec le DataOps, vous construisez une machine industrielle agile et fiable. Cette transformation nécessite expertise technique Microsoft et accompagnement du changement culturel.
Askware accompagne cette transformation en croisant maîtrise de l'écosystème Microsoft et compréhension des enjeux organisationnels. Nous transformons vos pratiques pour accélérer durablement votre valorisation data.
Vos projets data s'éternisent et vos équipes sont submergées ? Demandez un atelier de cadrage pour évaluer votre maturité actuelle et définir votre roadmap d'industrialisation.
Le DataOps applique les principes DevOps au domaine des données pour industrialiser leur production. Concrètement, ça signifie automatiser vos pipelines data, tester systématiquement la qualité, versionner tout votre code sur Git, et déployer de manière continue. L'objectif ? Passer de plusieurs mois à quelques semaines pour livrer une nouvelle source de données exploitable, tout en garantissant une qualité constante. C'est transformer un processus artisanal en chaîne de production industrielle.
Le Data Engineering est une discipline technique, un ensemble de compétences pour construire et maintenir des pipelines de données. Le DataOps est une méthode de travail qui définit comment exercer ces compétences de manière industrielle. Un data engineer sans DataOps écrit du code qu'il teste manuellement et déploie en copiant-collant. Avec le DataOps, il version son code sur Git, le teste automatiquement à chaque modification et le déploie via CI/CD. Le Data Engineering répond au "quoi faire", le DataOps répond au "comment le faire efficacement à l'échelle".
Commencez petit avec un pipeline critique mais pas trop complexe pour obtenir un quick win visible rapidement. Provisionnez Azure Data Factory pour l'orchestration et Azure DevOps pour le versioning et le CI/CD. Versionnez votre code de pipeline sur Git, écrivez quelques tests automatisés basiques, et configurez un déploiement automatique vers un environnement de test. Une fois ce premier pipeline industrialisé et les bénéfices démontrés, documentez le processus et étendez progressivement à d'autres pipelines. L'approche progressive par vagues fonctionne beaucoup mieux qu'un big bang qui épuise les équipes.
Nos experts partagent leur vision des meilleures pratiques et tendances technologiques pour réussir votre transformation digitale.


