
How to build a “Customer Data Platform” (CDP) strategy with Microsoft?
Customer Data Platform: Build your CDP strategy with Microsoft Customer Insights. Unification, segmentation, activation. Expert guide.
When a sales department requests a dashboard integrating e-commerce data from the data team, the data team often has a minimum duration of 6 months. Especially when the steps are performed manually, from extraction to deployment. However, the results are quickly felt: chronic slowness, exhausted teams, frustrated business. The artisanal approach does not scale.
The DataOps apply the industrialization principles of DevOps to data. In some cases, you can spend from 6 months to a few weeks to deliver a usable source, with guaranteed quality and a serene team.
In this article, we decipher this approach: definition and positioning, business challenges, fundamental practices, implementation in the Microsoft ecosystem and gradual deployment methodology.

DataOps refers to the set of practices that apply DevOps principles to the data domain. More concretely, it transforms data production from an artisanal and slow process into an agile and reliable industrial chain.
This approach can be summed up by the following educational formula: DataOps = Data + DevOps + Agile Method + Lean Manufacturing. You are borrowing:
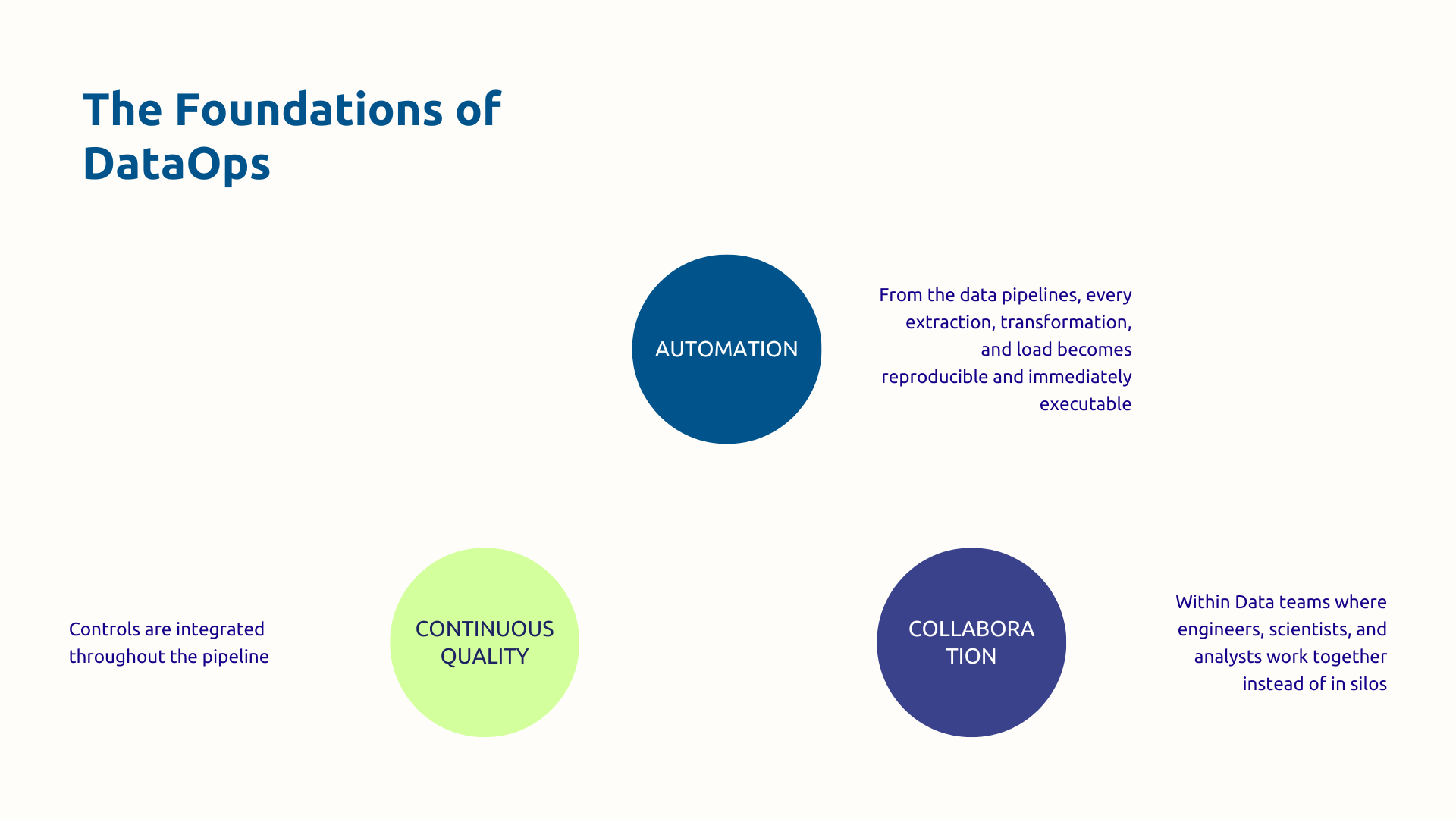
So, The DataOps corresponds to a real culture, to a set of practices supported by tools. Its scope covers the entire chain: from the ingestion of sources to consumption by business users, including transformation, quality, governance and monitoring.
Confusion between these terms is common. The Data Engineering is a technical discipline that consists in building ETL pipelines and data architectures. It's the “what”: the skills needed to manipulate and transform data at scale.
For its part, the DataOps is a method for industrializing data engineering. It's the “how”: the practices to perform data engineering in an industrial and reproducible way. A data engineer who applies DataOps principles versions his code, automatically tests it and deploys it via CI/CD.
As for MLops (Machine Learning Operations) is a subset of DataOps focused specifically on machine learning models: deployment, monitoring and maintenance of ML models in production. DataOps has a broader scope that encompasses the entire data chain, whether you are doing ML or not.
First of all, the slowness. Indeed, each new data pipeline becomes a project lasting several months while your business waits.
This is getting worse with organizational silos where data engineers, scientists and analysts each work in their own corner, without collaboration or knowledge sharing
In addition, The quality of the data remains uncertain because you test manually at the end of the line and the errors are discovered in production by the end users.
In addition, you are doomed to start from scratch with each project: the code is not documented, shared, or versioned. So it is not not reusable.
As a final symptom, this artisanal approach cannot absorb the growing demand. As a result, your data team becomes overwhelmed and becomes a bottleneck. In fact, according to numerous industry studies, data scientists spend up to 70% of their time preparing data and only 30% doing analysis and driving machine learning. They are from valuable skills that are thus squandered.

Accelerating time-to-insight is the most immediate benefit. This is explained by:
For example, in some projects, where the integration of a new e-commerce source required 6 months (connector development, transformation, quality control, production), DataOps can reduce this delay to two weeks thanks to a reusable connector, automated transformations, deployment via CI/CD and continuously controlled quality.
By the way, the quality guarantee Through DataOps, it requires systematic certainty since, first, automated testing verifies each pipeline before production: expected volume, correct format, data consistency, compliance with business rules.
In addition, continuous monitoring makes it possible to trigger automatic alerts if an anomaly is detected. Finally, observability provides complete traceability via data lineage: you know where the data comes from and how it has been transformed. You can be confident again and make business decisions with confidence.
The third major benefit of DataOps is the democratization of access to data via supervised self-service, which changes organizational dynamics.
So, your marketing teams create their own Power BI reports on certified quality data, without waiting two months for a data engineer to build a pipeline for them.
Likewise, collaboration becomes fluid thanks to the data code shared on Git, the automatic documentation and the data catalog accessible to all. Not to mention feedback loops, which allow businesses to quickly report their needs and deploy patches.
Automation is nothing less than the technical foundation of DataOps. Infrastructure as Code allows you to treat your data pipelines as versionable and reproducible code, defined in JSON, YAML, or Python. No need to manually reconfigure each environment.
Through tools like Azure Data Factory (or Airflow for hybrid architectures) you Orchestrate the sequencing of tasks, the scheduling of executions and the automatic recovery from error. Know that automation covers all stages:
Your Azure Data Factory pipeline is defined in an ARM template in code form. It takes data from the Salesforce API, transforms it with Spark, and then loads it into Synapse. This code is versioned on Git and deployed automatically via Azure DevOps. Are you changing anything? A simple Git commit triggers the automatic execution of the tests and then the deployment.
Thanks to unit tests, each transformation is checked separately: the SQL function that aggregates sales must produce the expected result on a known data set. Then, with the integration tests, we validate the complete end-to-end pipeline on test data.
Finally, it is through the consistency and quality tests that the automation of the verification of business rules is made possible:
Frameworks such as Great Expectations, one of the reference tools for data validation, make it possible to define these expectations in the form of criteria and then validate them automatically.
Attention, for this to be a continuous monitoring, these tests must be carried out at each commit on Git, before each deployment to production and even during production.
For example, for a pipeline that transforms sales data: Unit tests verify that SQL aggregations produce the correct totals. Consistency and quality tests validate that the sum of sales from all stores equals the national sum. Data quality checks verify that no turnover is negative and that no date is in the future.
Git stores all of your data code : ETL pipelines, transformations, tests, documentation. Each change is traced: who made it, when, and why.
In addition, the branches/pull requests workflow structures collaboration. In fact, you develop a new feature on a dedicated branch, you test, then you open a pull request for review by a senior data engineer who validates the approach before merging. This Peer Review guarantees quality and disseminates knowledge.
With complete traceability, you are always in a position to know who has modified this or that transformation. Therefore, the Rollback becomes trivial because at the slightest problem detected you only have to restore the previous version in one click.
In the Microsoft ecosystem, Azure Repos facilitates this version management for your data assets.
You can't manage what you don't measure. Observability transforms an opaque data platform into a transparent and manageable system.
Monitoring encompasses three dimensions:
Automatic alerting is a feature that will alert your team before problems become critical.
The Data lineage completes the system because it involves tracking the origin of the data and all the transformations applied. When a problem arises, by using this feature, you can instantly go up the chain to identify the source rather than looking blindly.
In the Microsoft ecosystem, all this observability arsenal is based on Azure Monitor and Application Insights for technical metrics, Microsoft Purview for data lineage, and Power BI for management dashboards. These capabilities are now largely integrated into Microsoft Fabric.
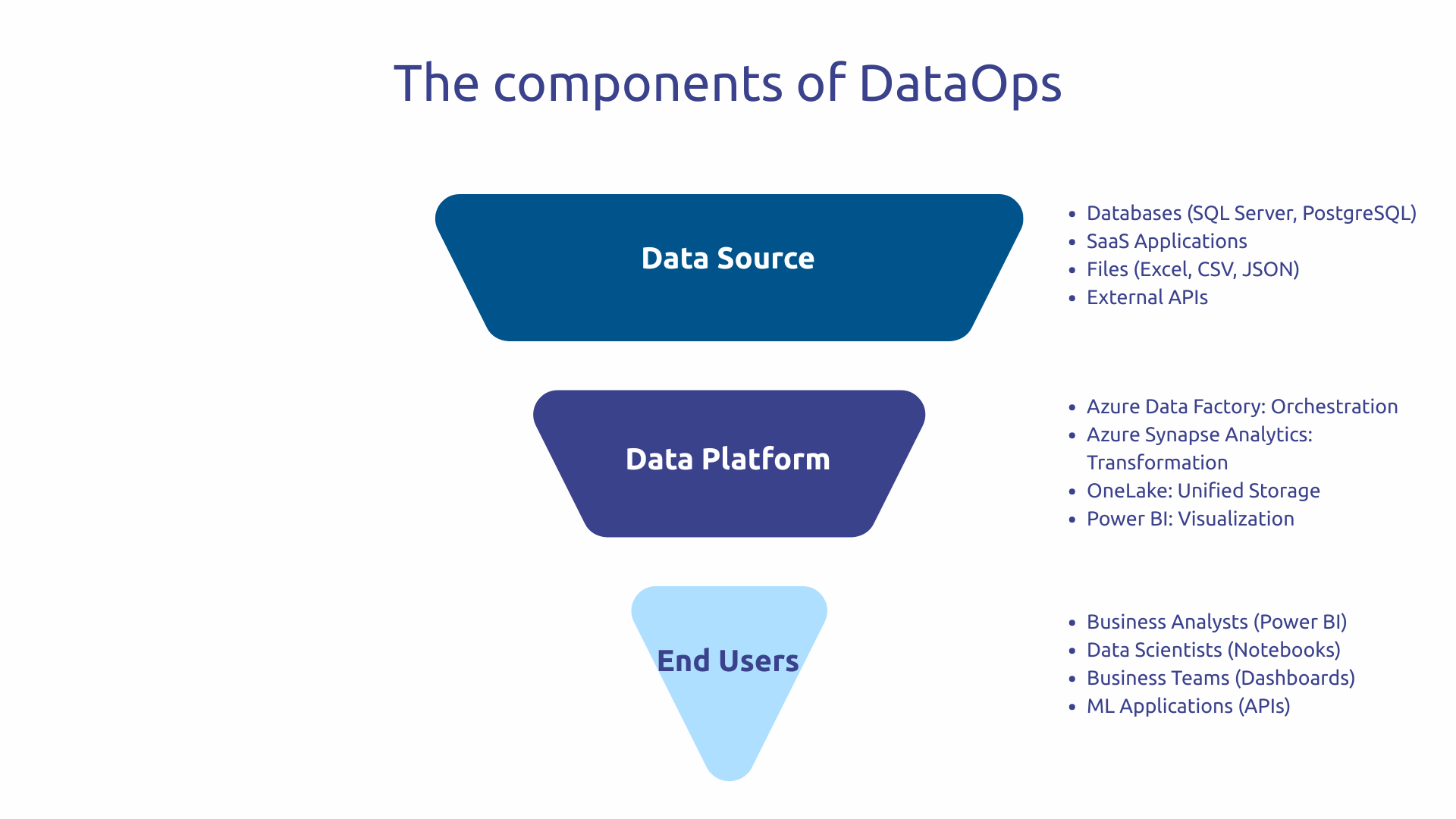
Azure Data Factory (ADF) orchestrate your data pipelines with more than 90 native connectors to various sources: databases, APIs, files, SaaS applications. This wealth avoids the development of custom connectors for each source.
At the same time, Azure Synapse Analytics combines a data warehouse and advanced capabilities: powerful analytical queries and Spark transformation power for large volumes. Together, ADF and Synapse form the extraction-transformation duo at the heart of your data chain.
However, what turns these tools into real DataOps platforms is their native CI/CD integration :
Azure DevOps brings just this automation and deployment dimension:
Fabric unified in a complete SaaS platform: data engineering, data warehouse, data science, real-time analytics and Power BI. No need to juggle between several separate services.
This effort is based on OneLake, a unified logical storage layer for all of your data in a single data lake. This centralization eliminates data silos that traditionally complicate governance and slow access.
But the decisive DataOps advantage of Fabric is its integration Git native. You version all Fabric content: pipelines, notebooks, semantic models, reports. This “Git-first” approach anchors DataOps at the very core of the platform rather than leaving it as an optional layer.
So the developer experience becomes modern and consistent. Whether you're doing data engineering, data science, or reporting, you're working in a unified environment with the same versioning, testing, and deployment practices.
Any DataOps transformation starts with understanding exactly where you are today.
So start with map your data assets : all your data sources, current flows, and existing pipelines. This overview often reveals surprises: forgotten sources, redundant flows, orphan pipelines. Then identify your pain points by asking yourself the right questions: where are you wasting the most time? What pipelines break regularly? Assess your current maturity on a spectrum ranging from completely manual to fully automated.
Then select a critical pipeline to get a quick win. This is a sufficiently important pipeline for business but not too technically complex and on which the improvement will be visible immediately. This first victory serves to demonstrate the value of DataOps and to give impetus for the future.
Then, you build the foundations of your DataOps platform. Provision Azure infrastructure : Data Factory, Synapse, and Azure DevOps. Then configure your multi-stage CI/CD environments: development to experiment, test to validate, production to deliver. Azure DevOps pipelines automate promotion between these environments.
Establish standards common to the team : how to structure the data code, what naming conventions, what tests are mandatory. Formalize data contracts that clarify expectations between data producers and consumers. Training teams in DataOps practices is critical: your data engineers need to understand Git, CI/CD, and automated testing.
Finally, define your success metrics to measure your progress: time-to-market for new pipelines, deployment success rate, incident resolution time.
Gradually expand the perimeter beyond pilot pipelines. You industrialize new data domains, you integrate new sources, you automate new processes. This expansion takes place in successive waves, consolidating what has been achieved at each stage rather than transforming everything at once.
Afterwards, optimize your pipelines and reduce your cloud costs. In fact, monitoring data reveals inefficient pipelines that consume too many resources. You optimize, you size correctly, you eliminate waste.
At the same time, cultivate continuous improvement through regular reviews. The team analyzes what worked well, what worked less well, and what needs to be adjusted. These sessions create ongoing collective learning. Over time, you evolve towards advanced capabilities: real-time streaming, ML automation with MLOps, advanced performance optimization.
Finally, Measure ROI to demonstrate the value created. Compare your current metrics to the initial metrics: time-to-market divided by how much? Incident rate reduced by what percentage?
Where you suffer from endless projects, recurring incidents and exhausted teams, with DataOps, you build an agile and reliable industrial machine. This transformation requires Microsoft technical expertise and support for cultural change.
Askware supports this transformation by combining mastery of the Microsoft ecosystem and understanding of organizational issues. We are transforming your practices to sustainably accelerate your data valorization.
Are your data projects dragging on and your teams overwhelmed? Request a framing workshop to assess your current maturity and define your industrialization roadmap.
DataOps applies DevOps principles to the field of data to industrialize their production. In concrete terms, this means automating your data pipelines, systematically testing quality, versioning all your code on Git, and deploying on an ongoing basis. The objective? Spend from several months to a few weeks to deliver a new usable data source, while ensuring consistent quality. It is to transform an artisanal process into an industrial production chain.
Data Engineering is a technical discipline, a set of skills for building and maintaining data pipelines. DataOps is a working method that defines how to exercise these skills in an industrial way. A data engineer without DataOps writes code that he tests manually and deploys by copy and paste. With DataOps, he versions his code on Git, automatically tests it with each modification and deploys it via CI/CD. Data Engineering answers the “what to do”, DataOps answers the “how to do it effectively at scale”.
Start small with a critical pipeline but not too complex to get a visible quick win quickly. Provision Azure Data Factory for orchestration and Azure DevOps for versioning and CI/CD. Version your pipeline code on Git, write some basic automated tests, and set up automatic deployment to a test environment. Once this first pipeline is industrialized and the benefits are demonstrated, document the process and gradually extend to other pipelines. The progressive wave approach works much better than a big bang that exhausts teams.
Our experts share their vision of best practices and technological trends to ensure the success of your digital transformation.


