
Comment bâtir une architecture cloud IT performante et durable ?
Architecture cloud performante et durable : principes, bonnes pratiques Azure, et méthodologie pour aligner IT et business. Guide expert.
Vos applications ne tombent plus en panne mais se dégradent lentement, silencieusement, jusqu'à ce qu'un utilisateur se plaigne. À ce moment-là, l'incident s’est déjà produit et vous le découvrez après vos clients.
Ceci est le quotidien de nombreux DSI qui pilotent des SI hybrides car le monitoring traditionnel a été conçu pour un autre monde, celui des monolithes stables et des architectures prévisibles. Or, face à la complexité des architectures cloud actuelles, il ne suffit plus.
L'observabilité informatique promet de changer la donne. Cet article aborde en détail ce qu'elle est, présente ses trois piliers et montre comment l'écosystème Azure permet de l'implémenter concrètement dans un SI hybride.

L'observabilité est un concept issu de la théorie du contrôle : un système est dit observable si son état interne peut être déduit à partir de ses sorties. Transposé à l'IT, cela signifie la capacité à comprendre ce qui se passe à l'intérieur de vos systèmes en analysant ce qu'ils produisent (à savoir les logs, les métriques et les traces).
Mais ce qui distingue fondamentalement l'observabilité du monitoring classique, c'est sa capacité à répondre à des questions que vous ne vous étiez pas encore posées. Le monitoring surveille ce que vous avez décidé de surveiller à l'avance tandis que l'observabilité vous permet d'explorer des comportements inattendus, d'enquêter sur des causes inconnues.
Pour prendre une analogie, le monitoring s’apparente au tableau de bord d'une voiture car il affiche les indicateurs prédéfinis (température, vitesse, niveau d'huile, etc.) De son côté, l’observabilité fonctionne plutôt comme la boîte noire d'un avion : elle enregistre tout, pour comprendre n'importe quel scénario après coup.
Le monitoring classique repose donc sur le principe suivant : on définit ce qu'on veut surveiller, on pose des seuils, on reçoit des alertes. Cette approche fonctionne très bien sur des systèmes stables et prévisibles mais devient insuffisante dès que l'architecture se complexifie.
Prenons un incident typique : votre application est lente. Votre monitoring vous signale que le CPU d'un serveur est élevé. Or, il ne vous dit pas pourquoi : ni la requête en cause, ni le ou les utilisateurs impactés, ni la dépendance aval saturée. Vous passez donc des heures à chercher ces informations.
Ces insuffisances proviennent de limites structurelles :
De fait, le monitoring classique est adapté aux architectures monolithiques des années 2000 mais n'a pas été conçu pour les architectures cloud distribuées qui ont cours aujourd'hui.
Dans un SI hybride moderne, une requête utilisateur va probablement traverser, par exemple, une application on-premise, un API gateway Azure, trois microservices conteneurisés, une base de données managée et un service tiers d'authentification. Le tout en quelques centaines de millisecondes.
Dans ce contexte, la complexité est désormais la norme : les ressources sont éphémères (des conteneurs qui apparaissent et disparaissent selon l'auto-scaling), les déploiements sont fréquents (jusqu'à plusieurs releases par jour dans les organisations les plus matures), et les dépendances sont multiples. Dès lors, sans observabilité, piloter ce type de SI revient à conduire les yeux bandés.
Les enjeux business sont de taille : chaque minute d'indisponibilité a un coût mesurable, et une dégradation de la performance perçue suffit à faire abandonner un parcours client. Les utilisateurs ne tolèrent plus les lenteurs et les équipes IT subissent la pression pour garantir des SLA de plus en plus stricts dans un environnement de plus en plus complexe.
Les logs sont les enregistrements horodatés de tout ce qui se passe dans vos systèmes : erreurs, transactions, actions utilisateurs, changements d'état. Ce sont eux qui répondent aux questions “Qui ? Quoi ? Quand ? Où ?”
Un log structuré (au format JSON) est bien plus exploitable qu'un log en texte libre : il peut être indexé, filtré et corrélé automatiquement. Ainsi, une fois centralisés dans un espace unique, les logs provenant de toutes vos sources (applications, infrastructure, sécurité, audit) deviennent un outil d'investigation redoutablement efficace.
Même si les volumes peuvent être considérables, que les coûts de stockage s'accumulent et qu'il faut distinguer le signal du bruit, pourvu que vos logs soient bien configurés, vous serez en mesure de retracer exactement ce qui s'est passé lors d'un incident. Par exemple, chaque étape d'une transaction e-commerce, de l'ajout au panier jusqu'à la confirmation de paiement.
Les métriques sont des mesures numériques effectuées sur une période donnée : utilisation CPU, latence, taux d'erreur, nombre de requêtes par seconde. Elles répondent à la question « Combien ? » et vous permettent de visualiser la santé globale de vos systèmes.
Les métriques ont pour principaux avantages un faible coût de stockage et une capacité d'agrégation efficace. Grâce à tout cela, un graphique de latence sur 24 heures révèle immédiatement un pic anormal pendant les heures de pointe. De plus, les alertes basées sur des seuils (ou mieux, sur la détection d'anomalies) permettent une réaction rapide.
Du côté des limites, les métriques perdent en granularité et manquent de contexte. En effet une métrique isolée vous dit qu'il se passe quelque chose, mais rarement pourquoi. C'est là qu'intervient le troisième pilier.
Le tracing distribué permet de suivre le parcours complet d'une requête à travers tous les services de votre architecture. À chaque étape (appelée span), on enregistre la durée et les métadonnées de l'appel. L'ensemble des spans constitue une trace complète, visualisée sous forme de diagramme waterfall.
Imaginez un achat en ligne qui enchaîne 15 fois la séquence de requêtes : catalogue → panier → vérification stock → paiement → notification. Grâce à la trace vous savez que le service de paiement répond en 1,8 seconde alors que tous les autres répondent en moins de 50 millisecondes. Vous avez ainsi identifié le goulot d’étranglement en quelques clics.
À ce sujet, le standard OpenTelemetry s'est imposé comme la référence pour instrumenter les applications de manière portable et interopérable. Il est supporté nativement dans Azure, notamment via Azure Monitor et les SDK compatibles OpenTelemetry.
Pris séparément, logs, métriques et traces sont déjà des outils utiles. Corrélés, ils deviennent puissants.
Pour illustrer, si on considère le workflow type suivant :
Ainsi, des heures de diagnostic manuel peuvent être réduites à quelques minutes d'investigation ciblée.
Or, cette corrélation est impossible avec des outils silotés car elle requiert une plateforme unifiée qui fait circuler et relie les trois types de données. C'est précisément ce que propose l'écosystème Azure.

Azure Monitor est le hub central de toute stratégie d'observabilité sur Azure. En effet, il collecte, agrège et analyse les données de télémétrie provenant de l'ensemble de votre environnement : ressources Azure natives, applications, infrastructure on-premise via Azure Arc, et même d'autres clouds.
Toutes les données convergent vers un espace de stockage centralisé (Log Analytics workspace), depuis lequel vous pouvez déclencher des alertes, créer des dashboards interactifs (workbooks), configurer l'autoscaling et générer des rapports. L'intégration est native avec l'ensemble des services Azure, ce qui réduit considérablement la charge d'instrumentation.
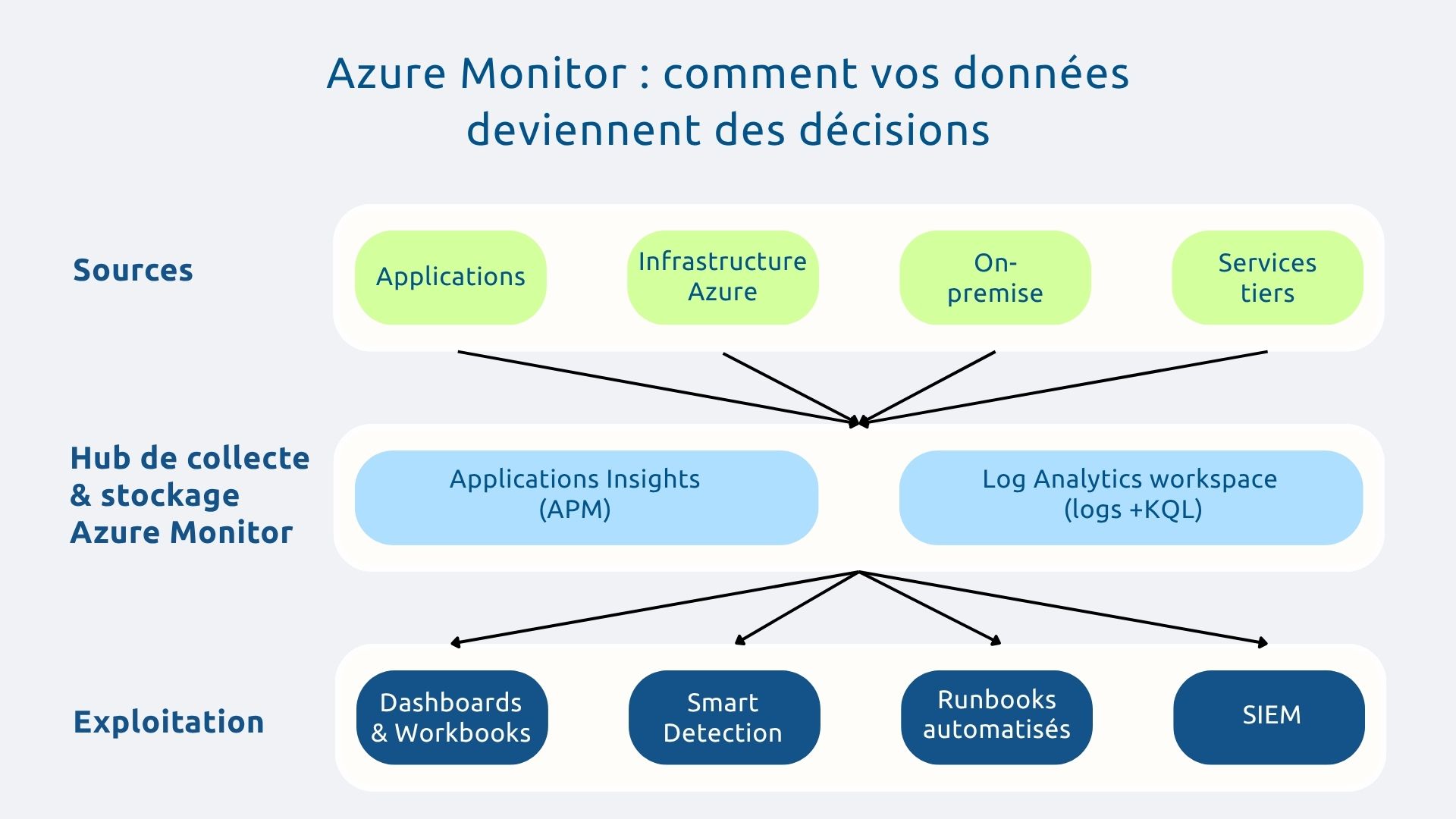
Application Insights est la solution d'APM (Application Performance Monitoring) de Microsoft. Elle offre une visibilité complète sur le comportement de vos applications : latence, taux d'erreur, dépendances, exceptions, requêtes lentes.
Sa fonctionnalité phare, l'Application Map, génère automatiquement une cartographie visuelle de votre architecture microservices et de toutes les dépendances, avec les temps de réponse associés. En un coup d'œil, vous voyez où se situent les goulots et quels composants sont en difficulté.
De plus, Application Insights supporte de nombreux langages, notamment .NET, Java, Node.js, Python et s'intègre nativement avec Visual Studio et Azure DevOps. Il inclut également des analytics sur le comportement utilisateur (sessions, parcours, pages vues) pour corréler la performance technique avec l'expérience réelle des utilisateurs.
Log Analytics est le moteur de requête qui transforme des téraoctets de données brutes en insights actionnables. Tous vos logs, quelle que soit leur source, sont centralisés dans un workspace unique, interrogeable via le langage KQL (Kusto Query Language).
Grâce à ce dernier, en quelques lignes, vous pouvez rechercher toutes les erreurs 500 des dernières 24 heures, les distribuer par service, calculer leurs corrélations avec des pics de trafic. Qui plus est, les requêtes peuvent être sauvegardées, transformées en alertes automatiques ou intégrées dans des dashboards.
Par ailleurs, la rétention des données est configurable selon vos besoins réglementaires et opérationnels. Enfin, Log Analytics s'intègre également avec Microsoft Sentinel pour les cas d'usage sécurité (SIEM).
Azure Monitor et ses composants ne fonctionnent pas seuls. L'écosystème s'enrichit de plusieurs outils complémentaires qui couvrent l'ensemble des besoins d'observabilité :
L'avantage de cette suite, c’est qu’elle est intégrée par design : pas besoin d'assembler des solutions tierces disparates et de gérer les frictions d'intégration car Azure offre un écosystème cohérent qui évite les silos d'outils ainsi que le shadow IT.

Avant d'instrumenter quoi que ce soit, posez-vous la question essentielle : qu'est-ce qui compte vraiment pour votre business ?
La réponse doit se formuler en :
SLI et SLO doivent être alignés sur les parcours utilisateurs critiques et les priorités métiers. Ce cadre, inspiré des pratiques Google SRE, garantit que l'observabilité génère des insights actionnables plutôt qu'un torrent de données sans signification.
L'instrumentation est l'investissement initial indispensable parce que de sa qualité dépend la valeur de l'observabilité que vous obtiendrez.
Côté applicatif, les SDK Application Insights et les bibliothèques OpenTelemetry permettent d'implémenter le tracing distribué, la collecte de métriques et les logs structurés avec un minimum de code.
Côté infrastructure, les agents Azure Monitor collectent automatiquement les données des VM, des conteneurs et des services managés.
On recommande d’effectuer cette étape progressivement : commencez par les services les plus critiques pour le business, validez les résultats, puis étendez. Standardisez les pratiques d'instrumentation pour que toutes les équipes produisent des données homogènes et corrélables.
La centralisation consiste à transformer une collection d'outils de monitoring disparates en véritable plateforme d'observabilité. Pour ce faire, configurez un Log Analytics workspace unique comme point de convergence de toutes vos sources de données.
La corrélation repose sur la propagation des identifiants de trace (trace IDs) à travers tous les appels de service. Quand un ID est partagé entre les logs, les métriques et les traces d'une même requête, la navigation entre les trois piliers devient fluide et instantanée.
L'Application Map se génère alors automatiquement depuis Application Insights, ce qui vous donne une visualisation en temps réel de votre architecture et de ses dépendances.
Un bon dashboard doit guider vers l'essentiel. Aussi, concevez des vues différenciées selon les audiences :
Pour rappel, les alertes doivent être basées sur vos SLO. Notez qu’Azure Monitor propose des capacités de détection intelligente pour identifier les comportements anormaux sans avoir besoin de configurer manuellement les seuils. Par ailleurs, en couplant ces alertes à des runbooks automatisés, on permet au système d'initier une remédiation sans intervention humaine sur les cas les plus courants.
De ce fait, on réduit l'alert fatigue en ne notifiant les équipes que pour des événements qui nécessitent réellement une action.
L'observabilité est autant une transformation culturelle que technique.
Cela implique d'assigner une ownership claire : chaque équipe est responsable de l'observabilité de ses propres services. De même, les post-mortems d'incidents deviennent des exercices d'apprentissage, documentés et partagés. Troisièmement, l'instrumentation doit faire partie de la définition du « done » dans les sprints de développement, c'est le principe du shift-left de l'observabilité.
Enfin, la valeur se mesure : MTTR (temps moyen de résolution), MTTD (temps moyen de détection), taux de disponibilité. Ces KPIs permettent de démontrer concrètement le retour sur investissement de la démarche et de maintenir l'adhésion dans la durée.
Les trois piliers corrélés dans une plateforme unifiée donnent la visibilité end-to-end qu'exigent les architectures modernes. Néanmoins, la technologie ne suffit pas : il faut une stratégie claire, une instrumentation rigoureuse et une culture d'équipe alignée.
En effet, à mesure que les SI gagnent en complexité, les organisations qui maîtrisent l'observabilité disposeront d'un avantage décisif : la capacité à garantir l'expérience utilisateur, à réduire les coûts d'incident et à innover plus vite, en toute confiance.
Votre stratégie de monitoring actuelle suffit-elle à piloter votre SI hybride ? Demandez votre audit à Askware pour identifier vos angles morts et construire votre feuille de route vers une observabilité complète.
Le monitoring surveille ce que vous avez décidé de surveiller à l'avance. L'observabilité vous permet d'enquêter sur des comportements que vous n'aviez pas anticipés. En pratique : le monitoring vous dit « quelque chose ne va pas », l'observabilité vous aide à comprendre pourquoi.
Les logs (événements détaillés), les métriques (tendances numériques dans le temps) et les traces distribuées (parcours complet d'une requête à travers vos services). C'est leur corrélation dans une plateforme unifiée qui produit une vraie observabilité.
Le MTTR est souvent élevé non pas parce que la résolution est complexe, mais parce que le diagnostic prend trop de temps. Une alerte sur une métrique vous amène directement aux traces concernées, puis aux logs précis. Le tout en quelques minutes plutôt qu'en quelques heures.
Nos experts partagent leur vision des meilleures pratiques et tendances technologiques pour réussir votre transformation digitale.

