
Automatisation IT : comment libérer la valeur du SI sans en perdre le contrôle ?
Découvrez comment automatiser votre IT pour gagner en efficacité tout en maintenant gouvernance et sécurité. Guide expert pour DSI.
Les SLA (Service Level Agreements) sont censés garantir la qualité de service. Or, dans la pratique, beaucoup d'organisations les signent sans vraiment comprendre ce qu'ils couvrent, comment les mesurer, ou quoi faire en cas de non-respect. En environnement cloud hybride, la complexité s'accroît : comment garantir un niveau de service end-to-end quand on mêle Azure, on-premise et SaaS tiers ?
Cet article décrypte ce que recouvrent vraiment les SLA, comment les piloter dans un contexte hybride, et pourquoi la résilience se construit dans l'architecture bien avant d'être inscrite dans un contrat.

Un Service Level Agreement, ou accord de niveau de service, est un engagement formalisé par un fournisseur de service (interne ou externe) auprès de ses utilisateurs. Il définit ce que le service doit garantir, comment cela se mesure et ce qui se passe si les engagements ne sont pas tenus.
Un SLA bien construit comprend donc plusieurs composantes indissociables, à savoir :
Il est important de bien distinguer le SLA externe, qui régit la relation avec un fournisseur cloud, un éditeur SaaS ou un prestataire, du SLA interne, qui formalise les engagements de la DSI vis-à-vis des directions métiers. Dans un environnement hybride, les deux coexistent, c’est pourquoi leur cohérence est essentielle.
Pour prendre un exemple de ce à quoi doit ressembler un SLA utile : « Disponibilité du CRM : 99,5 % mensuel (temps de réponse des pages inférieur à 2 secondes) résolution des incidents critiques en moins de 4 heures. » C’est parfait car c’est simple, mesurable et opposable.
Les KPI d'un SLA ne se valent pas tous. Certains sont faciles à mesurer mais peu représentatifs de l'expérience réelle des utilisateurs. D'autres, plus complexes à calculer, reflètent précisément l'impact métier d'une dégradation.
Les indicateurs les plus courants sont :
Dans tous les cas, choisissez les KPI qui ont du sens pour vos métiers, pas ceux qui sont commodes à produire pour votre infrastructure.
Ces trois acronymes sont souvent confondus, alors qu'ils désignent des niveaux de lecture distincts.
Le SLI (Service Level Indicator) est la métrique brute mesurée en continu : le temps de réponse moyen observé est, par exemple, de 1,2 seconde. C'est le fait brut, sans jugement.
Le SLO (Service Level Objective) est l'objectif interne que vous vous fixez : le temps de réponse doit rester inférieur à 1,5 seconde dans 95 % des cas. C'est votre cible de fonctionnement normal.
Le SLA est l'engagement contractuel avec conséquences : si la disponibilité passe sous 99,5 %, des crédits sont accordés. C'est ce que vous promettez à l'extérieur.

La hiérarchie est en effet SLI (la mesure) → SLO (l'objectif interne) → SLA (l'engagement public) car les SLO doivent être plus exigeants que les SLA car c'est cette marge qui vous permet d'absorber les aléas sans déclencher de pénalités.
Les SLA d'Azure sont précis, publics et vérifiables mais leur portée est souvent mal comprise. De fait, Microsoft garantit la disponibilité de son infrastructure, pas de votre application.
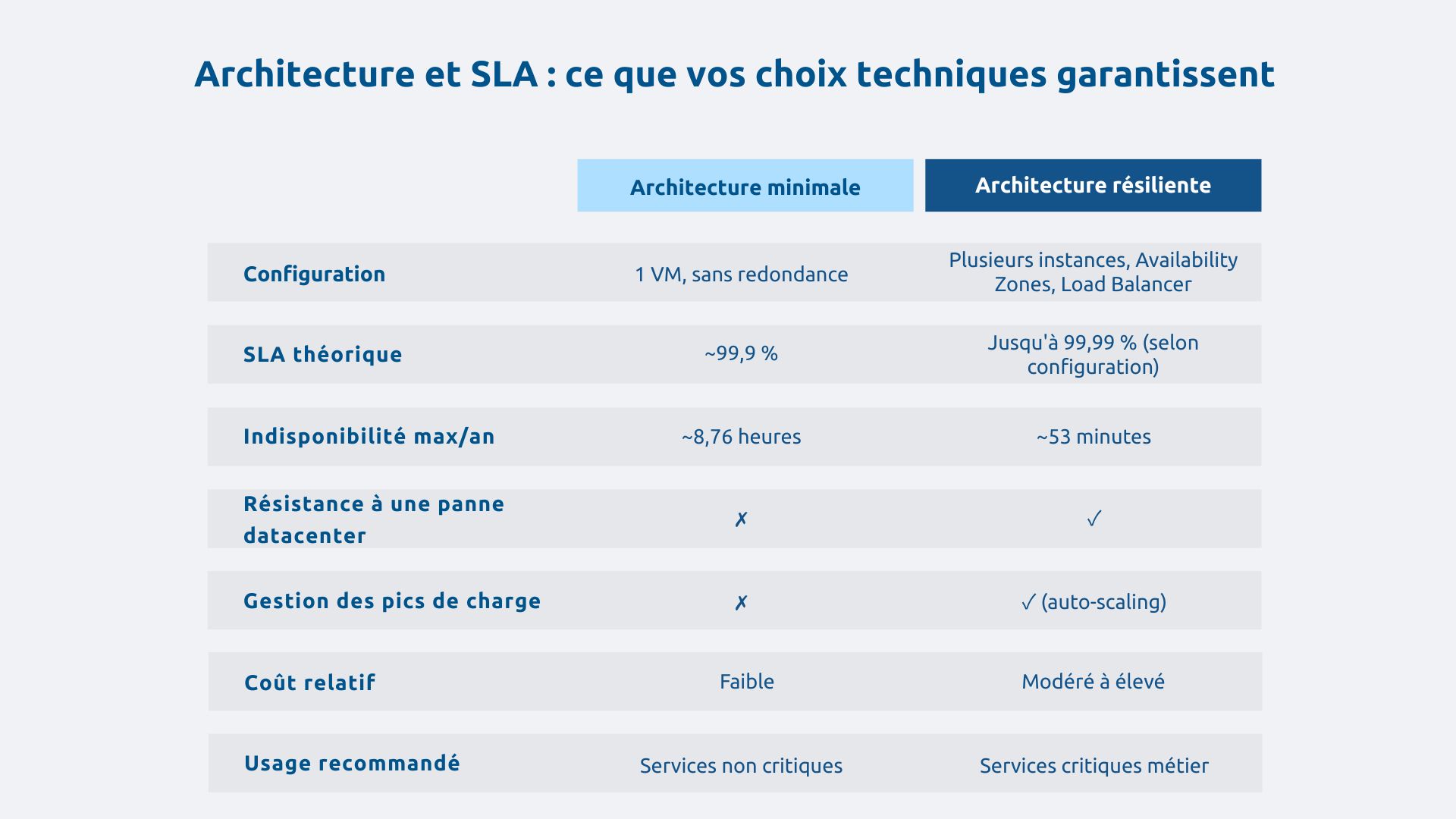
À titre indicatif, les SLA Azure pour les machines virtuelles se situent généralement autour de 99,9 % pour une instance seule, 99,95 % avec redondance locale, et jusqu'à 99,99 % selon certaines architectures multi-zones. Ces niveaux ne s'obtiennent pas tout seul, ils impliquent de respecter les bonnes pratiques d'architecture définies par Microsoft.
Gardez en tête que le SLA Azure ne couvre pas : vos bugs applicatifs, les mauvaises configurations, les erreurs humaines lors d'un déploiement ou les incidents sur des composants tiers.
En cas de non-respect avéré, les compensations prennent généralement la forme de crédits de service, dont le montant varie selon le service concerné et le niveau de manquement constaté. Suffisant pour dédommager mais rarement pour couvrir le coût réel d'une interruption métier.
Ainsi, le SLA du fournisseur cloud est une base au-dessus de laquelle il vous appartient de bâtir une architecture qui vous permettra d’atteindre vos propres objectifs de disponibilité.
Dans un environnement hybride, la qualité de service dépend de la chaîne de composants suivante : poste utilisateur, réseau d'entreprise, pare-feu on-premise, lien VPN ou ExpressRoute, Azure Virtual Network, couche applicative, base de données Dynamics 365. Chaque maillon a son propre niveau de fiabilité.
Qui est responsable quand l'incident se situe à la frontière entre votre réseau et Azure ? C'est précisément là que se forment la zone grise des responsabilités. D’où le besoin impératif de gouvernance, afin de ne pas piloter à l’aveugle, de cartographier chaque dépendance et d’attribuer des responsabilités pour chaque segment.
Les Availability Zones d'Azure permettent de distribuer les composants sur plusieurs datacenters physiquement indépendants, ce qui élimine les points de défaillance unique (SPOF).
En outre, le load balancing répartit la charge et absorbe la panne d'une instance sans interruption perçue. De son côté, l'auto-scaling adapte les ressources aux pics d'activité, pour éviter la saturation.
Enfin, le monitoring proactif vient compléter ce dispositif. Il vise à détecter une dégradation avant qu'elle ne devienne une panne, ce qui fait souvent la différence entre un incident invisible et un breach de SLA.
Sans monitoring, vous ne saurez jamais si vos engagements sont tenus, vous ne pourrez pas non plus le démontrer à vos parties prenantes.
L'écosystème Azure offre des outils complémentaires pour cette surveillance :
Le synthetic monitoring va plus loin : des tests automatisés simulent des parcours utilisateurs réels depuis différentes régions et vérifient que le service répond comme attendu. C'est la disponibilité perçue qui est mesurée, pas seulement la disponibilité technique de l'infrastructure. Ce type de monitoring s'articule naturellement avec une approche d'observabilité informatique plus large, qui offre une compréhension fine du comportement du SI en conditions réelles.
Les SLA concernent aussi les directions métiers. Ces dernières ont besoin de visibilité sur la qualité de service qu'elles reçoivent. Une visibilité qui doit être régulière, lisible et honnête.
Un rapport SLA mensuel efficace comporte à la fois :
Lorsqu’un SLA n'est pas respecté, mieux vaut expliquer les causes, quantifier l'impact, présenter les mesures correctives. En effet, c’est comme cela qu’on démontre la maturité de son organisation face à un incident.
Les revues de service régulières avec les métiers sont aussi l'occasion d'ajuster les SLA si les besoins ont évolué.
Même avec une architecture solide, des incidents surviennent. Ce qui met en avant les organisations matures, c'est moins leur capacité à éviter les pannes que leur capacité à les gérer.
Le processus doit être formalisé : détection, escalade, communication aux utilisateurs avec des estimations de retour réalistes, résolution, puis post-mortem. Même si ce dernier point est souvent négligé, l'analyse des causes profondes (Root Cause Analysis) après un breach de SLA permet de comprendre ce qui s'est passé, pourquoi les mécanismes de protection n'ont pas suffi, et comment éviter la récurrence. Sans cette discipline, les mêmes incidents ont tendance à se reproduire.
Un exemple : indisponibilité d'un CRM pendant 2h30 un mardi matin avec breach du SLA 99,9 %. Cause identifiée : saturation de la base de données sous charge inhabituelle. Actions correctives : migration vers un SKU supérieur, mise en place de l'autoscaling, seuil d'alerte abaissé à 75 % de capacité.
Pour des SLA supérieurs à 99,95 %, une architecture mono-région atteint ses limites structurelles. La distribution géographique devient alors la seule option viable pour des services critiques dont l'indisponibilité est inacceptable.
Azure Traffic Manager (routage DNS global) ou Azure Front Door (routage applicatif avec WAF) permettent d'orienter automatiquement le trafic vers une région disponible en cas de défaillance.
Ce niveau d'architecture a un coût, à la fois financier et en complexité opérationnelle. Il doit être réservé aux services dont l'interruption aurait un impact métier majeur. Pour les services moins critiques, une architecture mono-région bien dimensionnée est généralement suffisante. La décision doit être guidée par une analyse coût/risque, pas par une démarche systématique.
C'est précisément le type d'arbitrage qu'une architecture cloud performante et durable intègre dès sa conception.
Un SLA et un plan de reprise d'activité (PRA) sont deux sujets étroitement liés. Votre SLA définit ce que vous promettez en conditions normales ; votre stratégie de remédiation définit ce que vous pouvez tenir en cas de sinistre majeur.
Pour vous aider, il existe deux KPI de premier plan :
Notez que ces objectifs conditionnent directement les choix techniques : Azure Site Recovery pour la réplication des machines virtuelles, géo-réplication pour les bases SQL, sauvegardes automatisées configurées selon les fenêtres de rétention requises.
Une part significative des breachs de SLA trouve son origine non dans une défaillance technique, mais dans une erreur humaine : une configuration modifiée sans test préalable, une alerte ignorée, une sauvegarde oubliée. L'automatisation est la réponse structurelle à ce risque.
L'Infrastructure as Code garantit que les environnements sont toujours déployés de manière cohérente et reproductible, éliminant les dérives de configuration. Les mécanismes d'auto-healing permettent à Azure Monitor de déclencher automatiquement le redémarrage d'un service défaillant en quelques minutes, sans intervention humaine.
Les alertes automatiques et les escalades formalisées peuvent garantir, lorsqu'elles sont correctement configurées, que le bon interlocuteur soit notifié au bon moment avec la bonne information. L'automatisation IT appliquée au pilotage des SLA est d'ailleurs l'un des leviers les plus efficaces pour fiabiliser durablement la qualité de service.
Les SLA sont des outils de pilotage stratégique qui expriment, en engagements mesurables, la promesse que l'IT fait aux métiers.
Dans un environnement cloud hybride, cette promesse se construit aussi bien dans les choix d'architecture, que dans les pratiques de monitoring, que dans la rigueur des processus de gestion d'incidents, que dans la transparence de la communication avec les directions métiers. Chaque maillon compte, et la gouvernance de l'ensemble est aussi importante que la robustesse de chaque composant.
Vos stratégies IT actuelles sont-elles vraiment alignées sur vos enjeux métiers ? Contactez Askware pour un audit adapté à votre environnement et commencez à piloter votre qualité de service avec la rigueur qu'elle mérite.
Le SLI est ce que vous mesurez, le SLO est l'objectif interne que vous vous fixez, le SLA est l'engagement contractuel avec conséquences. Les SLO sont toujours plus exigeants que les SLA pour vous laisser une marge de sécurité.
La disponibilité de l'infrastructure Microsoft — datacenters, réseau, services managés. Pas vos applications, vos configurations, ni les composants tiers. Les compensations prévues (crédits sur facture) couvrent rarement le coût réel d'une interruption métier.
Documentez l'incident avec vos données de monitoring — ce qui suppose de l'avoir mis en place en amont — puis suivez le processus de réclamation contractuel dans les délais impartis. C'est aussi l'occasion d'analyser pourquoi votre architecture n'a pas compensé la défaillance.
Nos experts partagent leur vision des meilleures pratiques et tendances technologiques pour réussir votre transformation digitale.


